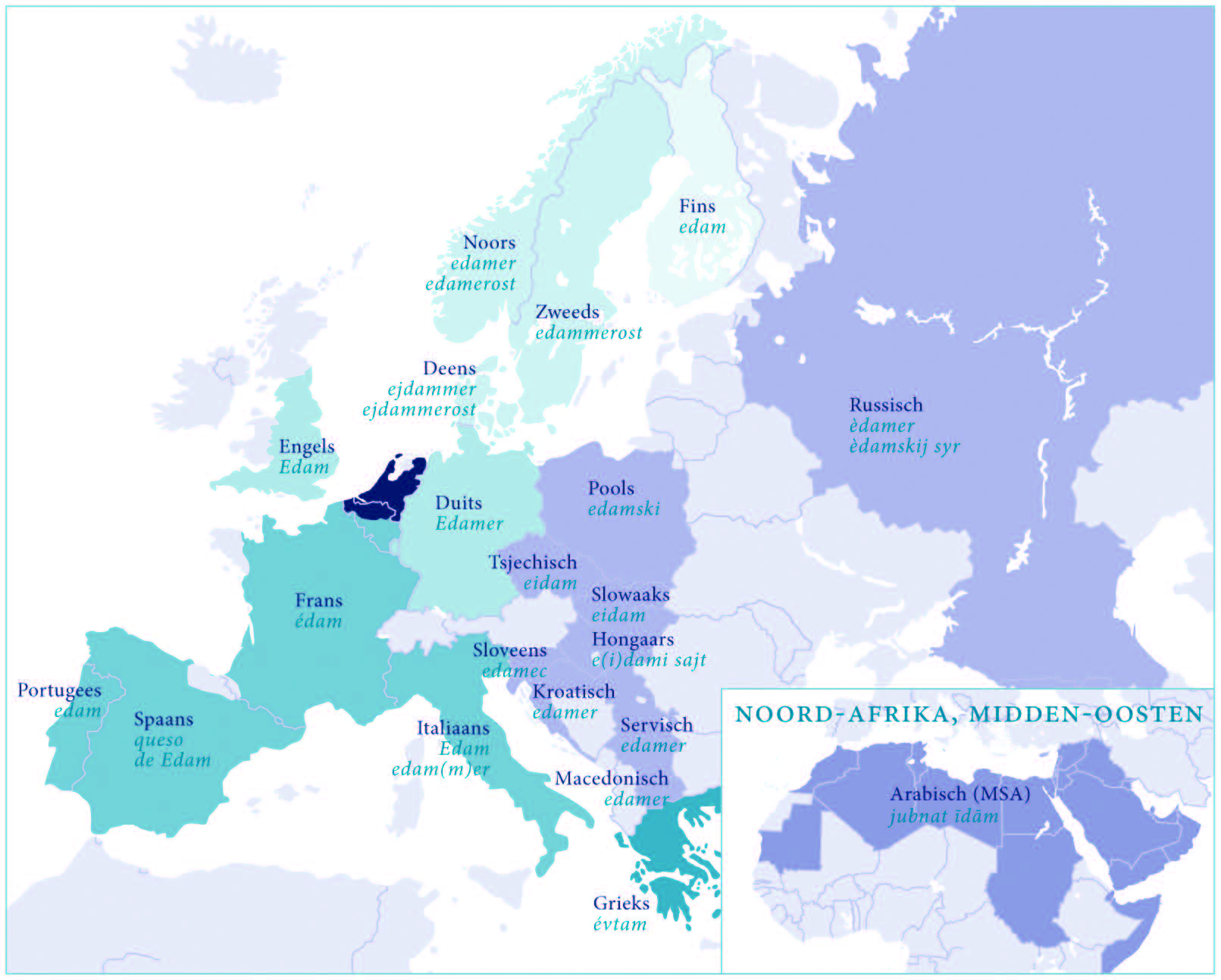
'Edammer'uit Nederlandse woorden wereldwijd, afb. van Louise van Swaaij
Hieronder staan links naar omvangrijke door mij samengestelde databanken:
– Couranten Corpus (dertien zeventiende-eeuwse kranten, samen ruim 18 miljoen woorden, gedigitaliseerd door vrijwilligers)
– DAGENTA (Database Geschiedenis Nederlandse Taalkunde), met 1500 historische werken over de Nederlandse taal
– Etymologiebank, met alle belangrijke etymologische publicaties van het Nederlands
– eWND (elektronische Woordenbank van de Nederlandse Dialecten)
– EDGeS Corpus, een parallel historisch bijbelcorpus met 36 bijbels in vier talen (Engels, Nederlands, Duits, Zweeds), samengesteld met Evie Coussé en Gerlof Bouma
– Gekaapte brieven, brieven van en naar scheepslieden eind 17e en eind 18e eeuw, gedigitaliseerd door vrijwilligers
– GLAD (Global Anglicism Database), met de Engelse leenwoorden in het Nederlands en in andere talen
– Meertens Kaartenbank, een overzicht van dialectkaarten en etnologische kaarten van de Lage Landen
– The Digital Pallas (database) en begeleidende website, een Russisch woordenboek uit 1790-1791 met 300 begrippen in 311 talen
– Transcriptor, online tool voor de omzetting van Russische en Oekraïense namen uit het cyrillisch of het Engels (met Pepijn Hendriks, Jasper Hooghwinkel en Thomas Milo)
– Uitleenwoordenbank, met 18.242 Nederlandse woorden die aan 138 talen zijn uitgeleend
– Vragenlijstenbank, met de vragenlijsten over dialectgebruik, volkskunde en naamkunde die door het Meertens Instituut tussen 1931 en 2005 zijn uitgezonden, en veel antwoorden daarop
– ongeveer 250 tekstedities van oude, waardevolle teksten, gedigitaliseerd door vrijwilligers; veelal ook te vinden op dbnl.org